Trap Aware MPC
Links ¶
Abstract ¶
We propose an approach to online model adaptation and control in the challenging case of hybrid and discontinuous dynamics where actions may lead to difficult-to-escape "trap" states, under a given controller. We first learn dynamics for a system without traps from a randomly collected training set (since we do not know what traps will be encountered online). These "nominal" dynamics allow us to perform tasks in scenarios where the dynamics matches the training data, but when unexpected traps arise in execution, we must find a way to adapt our dynamics and control strategy and continue attempting the task. Our approach, Trap-Aware Model Predictive Control (TAMPC), is a two-level hierarchical control algorithm that reasons about traps and non-nominal dynamics to decide between goal-seeking and recovery policies. An important requirement of our method is the ability to recognize nominal dynamics even when we encounter data that is out-of-distribution w.r.t the training data. We achieve this by learning a representation for dynamics that exploits invariance in the nominal environment, thus allowing better generalization. We evaluate our method on simulated planar pushing and peg-in-hole as well as real robot peg-in-hole problems against adaptive control, reinforcement learning, trap-handling baselines, where traps arise due to unexpected obstacles that we only observe through contact. Our results show that our method outperforms the baselines on difficult tasks, and is comparable to prior trap-handling methods on easier tasks.
Highlights ¶
- formally defines traps for a given controller
- high level TAMPC can be used with many lower level MPC methods
- introduces latent dynamics architecture that exploits training data invariants to be more robust to out of distribution test data
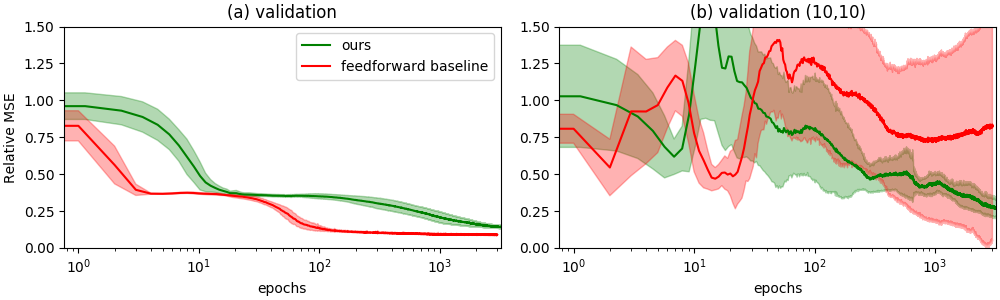
Learning curves on validation (left) and out of distribution (right) data with mean across 10 runs in solid and 1 standard deviation shaded. Lower relative MSE is better.
- capable of escaping traps that requires many control steps to escape (deep), or are close to the goal
- capable of completing tasks that adaptive control and reinforcement learning baselines find impossible while outperforming trap-handling baselines on planar pushing tasks
Bibtex ¶
@article{zhong2021tampc,
title={TAMPC: A Controller for Escaping Traps in Novel Environments},
author={Zhong, Sheng and Zhang, Zhenyuan and Fazeli, Nima and Berenson, Dmitry},
journal={IEEE Robotics and Automation Letters},
volume={6},
number={2},
pages={1447--1454},
year={2021},
publisher={IEEE}
}